


GPU availability and job interruption can be an issue for me, so this paper caught my attention. The paper is titled “Mirage: Towards Low-interruption Services on Batch GPU Clusters with Reinforcement Learning” and it proposes a method for reducing service interruptions on GPU clusters for deep learning jobs.
The tool is called Mirage. Mirage is a Slurm-compatible foundational model that uses statistical and reinforcement learning (RL) techniques to proactively provision resources to mitigate interruptions. To accomplish this, researchers alter the decoder transformer architecture to create a Mixture of Experts (MoE) of neural networks. The neural networks share the same network architecture to support scaling up of model capacity and determine ‘best-fit experts’ that optimize job trace analysis outputs for resource allocations.
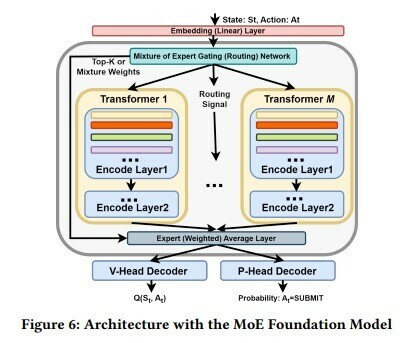
What’s really cool about this paper is how it investigates the use of Deep Q-Learning RL techniques to reenforce rewards to improve GPU queue wait times for a finite set of GPU resources to improve service continuity.
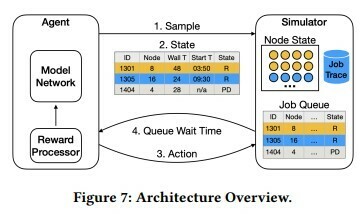
Mirage looks like a promising method to enable 23 to 76% more jobs on finite resources with zero interruptions!