

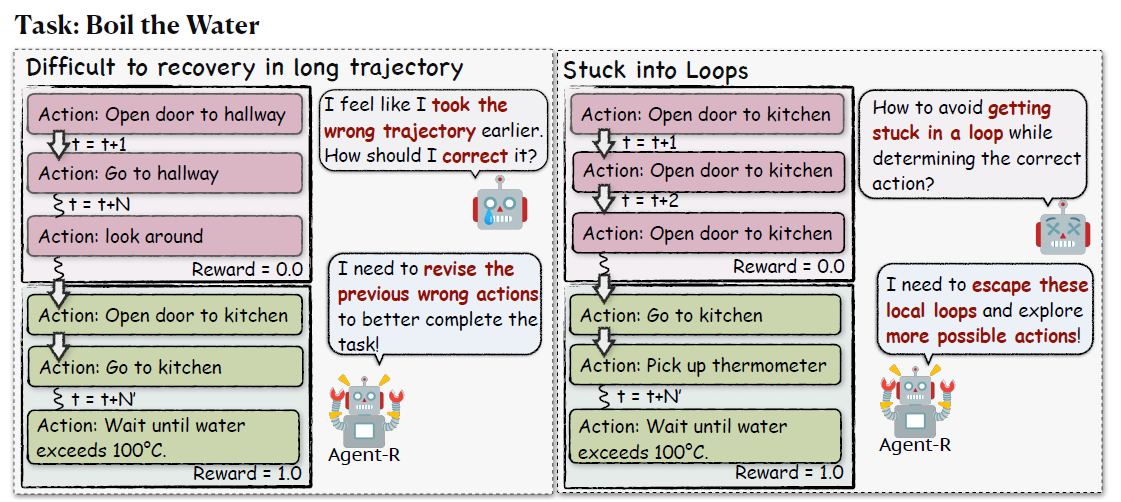
Imagine teaching a robot to boil water. It might first search for a pot, fill it with water, then place it on the stove. But what if it mistakenly turns on the microwave instead of the stove? Traditional AI agents often struggle to recover from such errors, leading to cascading failures. This is the problem Agent-R—a novel framework for training self-reflective language model agents—aims to solve.In this article, we’ll unpack the theoretical backbone of Agent-R by focusing on how this framework redefines error recovery in AI.
Why Error Recovery Matters in Interactive Environments
Most AI agents learn by mimicking expert trajectories (e.g., perfect step-by-step guides). But real-world tasks are messy. Errors are inevitable, and waiting until the end of a task to correct them is like letting a typo in a sentence propagate into a garbled paragraph.
The Core Challenge: Timely Intervention
- Problem: In multi-step tasks (e.g., crafting items in Minecraft or navigating a virtual lab), errors early in a trajectory compound, making recovery nearly impossible.
- Traditional Approach: Agents clone expert behavior but lack mechanisms to self-diagnose mid-task.
- Agent-R’s Insight: Enable agents to critique their own actions and rewrite trajectories while performing a task.
Breaking Down Agent-R’s Architecture
Agent-R combines Monte Carlo Tree Search (MCTS) with iterative self-training to create a self-improving system. Let’s dissect its components:
1. Monte Carlo Tree Search (MCTS): The Explorer
MCTS is a decision-making algorithm that simulates multiple future paths to choose optimal actions. Think of it as a chess player mentally exploring moves before committing.
- Four Phases:
- Selection: Navigate the tree using a balance of known rewards (exploitation) and untested paths (exploration).
- Expansion: Add new nodes (potential actions) to the tree.
- Simulation: Roll out hypothetical trajectories to their conclusion.
- Backpropagation: Update node values based on simulation outcomes.
In Agent-R: MCTS generates diverse trajectories—some successful (“good”), others flawed (“bad”). These form the training data for self-correction.
2. Model-Guided Critique Mechanism: The Editor
Here’s where Agent-R diverges from classic MCTS. Instead of waiting to evaluate a trajectory’s final outcome, the framework identifies the first actionable error using the agent’s current knowledge.
- Example: If an agent mistakenly searches for “blue shirts” instead of “light blue shorts,” the critique mechanism flags this step, splices the trajectory, and grafts a corrected path (e.g., revising the search query).
- Technical Twist: The actor model (agent’s policy) itself pinpoints errors, ensuring critiques align with its evolving capabilities.
3. Iterative Self-Training: The Feedback Loop
Agent-R doesn’t just fix errors—it learns from them. Each iteration refines two elements:
- Dataset Construction: Mixes “good” trajectories (high-reward paths) with “revision” trajectories (flawed paths corrected mid-task).
- Policy Optimization: Trains the agent to prefer error-correcting actions using a hybrid loss function:
L(θ)=η * Good Revision Trajectories +(1−η) * General Knowledge
Here, η balances task-specific learning vs. general reasoning.

Theoretical Innovations: Why Agent-R Works
Concept 1: Dynamic Trajectory Revision
Traditional methods train on static expert data. Agent-R’s revision trajectories teach agents to recover from mistakes, not just avoid them.
- Bad Trajectory: Actions leading to low rewards (e.g., wrong search terms).
- Good Trajectory: Optimal actions (e.g., correct search terms).
- Revision Trajectory: Combines the initial error, a critique signal (“I used the wrong search term”), and the corrected path.
Concept 2: Task-Aware Reflection
The critique mechanism isn’t a generic “try again”—it’s context-sensitive. By splicing trajectories at the first detectable error, Agent-R mimics human-like mid-task reflection.
Formulaic View:
Given an initial trajectory τi, a bad trajectory τb, and a good trajectory τg, the revision trajectory τr becomes:
τr=(τi,error segment,rs,corrected segment)
where rs is the revision signal (e.g., “Assistant: I need to correct my search term. Human: OK.”).
Concept 3: Cold Start Mitigation
Early training iterations face a “cold start” problem: few high-quality trajectories. Agent-R gradually raises the threshold (αα) for what counts as a “good” trajectory, ensuring the agent isn’t overwhelmed by noisy data.
Implications for AI Development
- Loop Prevention: By training on error recoveries, agents learn to avoid repetitive dead-ends (e.g., endlessly searching for nonexistent items).
- Scalability: The framework’s iterative nature allows continuous improvement without human intervention.
- Generalization: Mixing revision trajectories with general knowledge datasets (e.g., ShareGPT) enhances adaptability across tasks.
The Bigger Picture: Toward Self-Aware AI
Agent-R isn’t just about boiling water or crafting Minecraft items. It’s a paradigm shift in how AI agents handle uncertainty. By internalizing process critiques—not just outcomes—agents inch closer to human-like adaptability.Future Directions:
- Integrating external feedback (e.g., user corrections).
- Expanding to multimodal tasks (e.g., robots diagnosing physical errors).
Conclusion: The Art of Teaching Machines to Self-Reflect
Agent-R’s theoretical framework bridges the gap between rigid, expert-driven training and dynamic, real-world problem-solving. By treating errors as teachable moments—not failures—it equips AI agents with something akin to metacognition. For graduate students and researchers, this isn’t just a new tool; it’s a roadmap for building AI that learns like we do: iteratively, adaptively, and resiliently.
This article is based on the original research paper Agent-R: Training Language Model Agents to Reflect via Iterative Self-Training by Siyu Yuan, Zehui Chen, Zhiheng Xi, Junjie Ye, Zhengyin Du, and Jiecao Chen. All theoretical concepts, experimental results, and diagrams are sourced directly from the paper.