


A research paper by Ali Behrouz, Peilin Zhong and Vahab Mirrokni from Google Research introduce a groundbreaking neural network module that addresses the limitations of current models in handling long term dependencies. This work is a significant leap forward in the design of memory augmented architectures, offering theoretical and practical advancements in sequence modeling. Below we explore the theoretical underpinnings, technical innovations and experimental results of this advanced neural network module.
The Challenge of Long-Term Dependencies
Modern neural architectures like Transformers and recurrent neural networks (RNNs) have revolutionized sequence modeling. However, they face some challenges:
- Transformers:
- While effective at capturing short term dependencies through attention mechanisms, they are computationally expensive for long sequences due to quadratic complexity in context length.
- Their context window limits their ability to model long term dependencies
- Recurrent Models:
- Compress historical data into fixed-size states (e.g., vectors or matrices), which often leads to information loss when dealing with large contexts
- Linear recurrent models improve efficiency but fail to match the performance of Transformers in complex tasks
- Generalization and Scalability:
- Both architectures struggle with length extrapolation and reasoning over very long sequences, which are critical for real world applications like language modeling, genomics and time series forecasting.
Human Memory Inspiration
Inspired by the human brain’s distinct system for short term and long-term memory, they proposed a novel neural long term memory module that dynamically learns to memorize and forget during test time. This module forms the foundation of a new family of architectures called Titans, a system designed to:
- Combines short-term precision (attention) with long-term persistence (neural memory).
- Actively learns to memorize and forget during test time.
Theoretical Foundations: Memory as a Learning Paradigm
Memory Perspective
Memory is central to human cognition and learning. The authors draw inspiration from neuropsychology, where memory is viewed as a confederation of systems – short-term, working, and long-term memory. Each serving distinct functions but interconnected.
In machine learning:
- Short-term memory models immediate dependencies (e.g., attention mechanisms in Transformers).
- Long-term memory retains historical information over extended periods.
The proposed neural memory module combines these paradigms:
- It treats learning as a process for acquiring effective memory.
- It dynamically updates its parameters based on "surprise" metrics—quantifying how unexpected new inputs are relative to past data.
Surprise-Based Memorization
The core idea is that surprising events are more memorable. The model calculates surprise as the gradient of the loss function with respect to the input. The model identifies "surprising" inputs—those that deviate significantly from past patterns—and prioritizes them for memorization. The surprise metric is defined as the gradient of the loss function with respect to the input:
Where:
- Mt : Memory state at time t.
- ℓ: Loss function measuring prediction error.
- xt : Current input.
- θt : Data-dependent learning rate.
To avoid overemphasizing one surprising event and missing subsequent important data, the model uses a momentum-based mechanism:
Here:
- St: Accumulated surprise.
- ηt: Decay factor controlling how past surprises influence current updates.
Forgetting Mechanism
To prevent memory overflow and manage limited memory capacity effectively, an adaptive gating mechanism selectively forgets less relevant information:
Where αt is a data-dependent forget gate that determines how much of the old memory should be retained or discarded.
Persistent Memory
In addition to contextual memory, Titans include persistent memory—a set of learnable, input-independent parameters that store task-specific knowledge. This ensures that some information remains static across sequences.
Titans Architectures
The authors propose three ways to integrate the neural memory module into deep learning architectures:
1. Memory as Context (MAC)
- Treats historical memory as additional context for attention mechanisms.
- Combines current input with retrieved historical information and persistent memory before applying attention.
- Advantages:
- Balances short-term precision with long-term recall.
- Allows attention to decide which parts of historical memory are relevant.
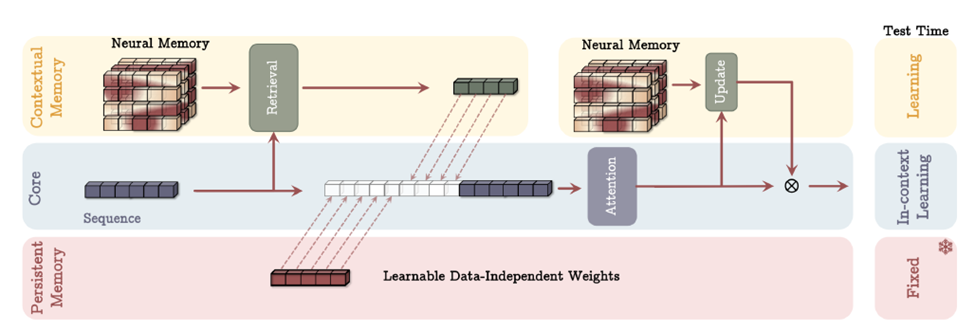
Image taken from the original paper Titans – Learning to Memorize at Test Times
Figure: Memory as a Context (MAC) Architecture.
This architecture includes three branches of (1) core, (2) contextual (long-term) memory, and (3) persistent memory. The core branch concatenates the corresponding long-term and persistent memories with the input sequence. Next, attention performs on the sequence and decides what part of the information should store in the long-term memory. At the test time, parameters corresponds to contextual memory are still learning, parameters corresponds to the core branch are responsible for in-context learning, and parameters of persistent memory are responsible to store the knowledge about tasks and so are fixed.
2. Gated Memory (MAG)
This variant combines sliding windows attention (short term memory) with neural memory using a gating mechanism:
Where y represents short term outputs, Mx represents long term outputs and ⊗ is a non-linear gating operation. The gating mechanism determines how much weight to assign to each type of memory. MAG provides precise control over how short term and long-term memories are integrated.
3. Memory as a Layer (MAL)
Here the neural memory module acts as an independent layer that compresses past and current contexts before applying attention. While simple than MAC or MAG, MAL lacks their flexibility and precision.
Experimental Results
The authors evaluate Titans on diverse tasks:
- Language Modeling: Titans outperform Transformers and modern recurrent models in perplexity and reasoning accuracy. They excel at capturing both short-term dependencies and long-range patterns in text data.
- Needle-in-a-Haystack Tasks: In tasks requiring retrieval of relevant information from extremely long distractor sequences (>2 million tokens), Titans achieve state-of-the-art performance by effectively leveraging their long-term memory capabilities.
- Time Series Forecasting: On benchmarks like ETTm1 and Traffic datasets, Titans demonstrate superior accuracy compared to Transformer-based and linear recurrent models.
- DNA Modeling: In genomics tasks requiring sequence modeling at single-nucleotide resolution, Titans show competitive performance with state-of-the-art architectures.
Theoretical Insights
- Expressiveness: Titans are theoretically more expressive than Transformers in state-tracking tasks due to their non-linear memory updates.
- Scalability: By tensorizing gradient descent operations, Titans achieve efficient parallel training on GPUs/TPUs while scaling to extremely large sequences (>2 million tokens).
- Trade-offs: Deeper memory modules improve performance but increase computational overhead, highlighting a trade-off between efficiency and effectiveness.
Conclusion
The Titans framework represents a paradigm shift in sequence modeling by introducing a scalable, adaptive approach to long-term memory. By combining short-term attention with neural long-term memory modules that actively learn during test time, Titans address key limitations of existing architectures while achieving state-of-the-art results across diverse domains.
Future Research:
- Exploring deeper neural memory modules for even greater expressiveness.
- Investigating hybrid architectures that further integrate attention mechanisms with neural memories.
- Applying Titans to applications like video understanding or multimodal modeling.