

Multi-agent systems have become increasingly important in solving complex problems through distributed intelligence and collaboration. However, coordinating multiple agents effectively remains a significant challenge, particularly in the field of reinforcement learning. In this article, we'll explore a novel approach called Shared Recurrent Memory Transformer (SRMT) that aims to enhance coordination in decentralized multi-agent systems.
The Challenge of Multi-Agent Coordination
Imagine a group of robots trying to navigate through a crowded warehouse. Each robot has its own goal and can only see what's immediately around it. How can they work together efficiently without bumping into each other or getting stuck? This is the essence of the multi-agent pathfinding problem.
Traditional approaches often struggle with this task, especially when the environment is complex or the number of agents is large. They may rely on centralized control, which doesn't scale well, or on explicit communication protocols, which can be difficult to design and implement.
Introducing SRMT: A New Approach
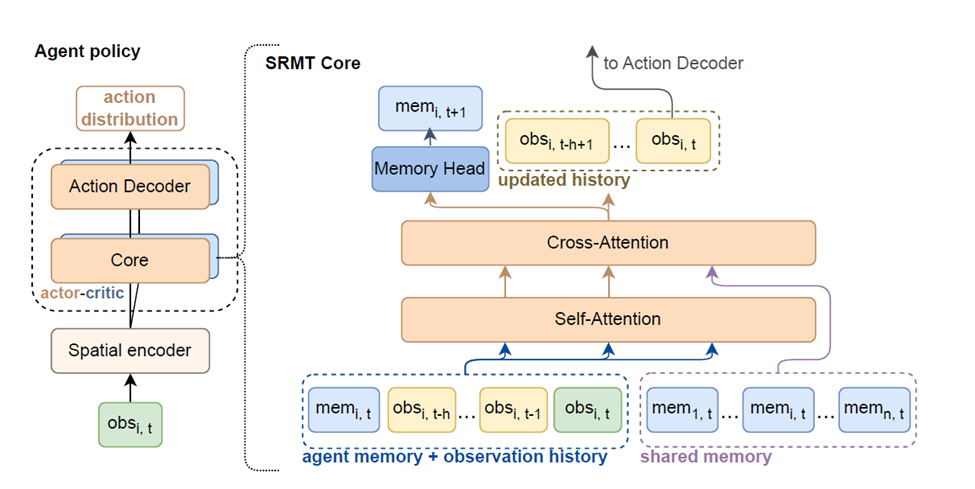
The Shared Recurrent Memory Transformer (SRMT) takes inspiration from how our brains work. Just as different parts of our brain can share information through a "global workspace," SRMT allows agents to share information implicitly through a shared memory space.
Here's how it works:
- Each agent has its own "personal" memory, which it updates based on what it observes.
- These personal memories are then pooled together into a shared space.
- All agents can access this shared memory, allowing them to incorporate global context into their decision-making.
This process happens continuously as the agents move and interact with the environment.
Why SRMT is Innovative
SRMT builds upon recent advances in transformer architectures, which have revolutionized natural language processing and other AI tasks. By adapting these powerful models to multi-agent reinforcement learning, SRMT offers several advantages:
- Implicit Communication: Agents don't need to explicitly send messages to each other. Instead, they share information naturally through their shared memory.
- Scalability: The approach can handle a large number of agents without requiring a centralized controller.
- Flexibility: SRMT can be applied to various multi-agent tasks, not just pathfinding.
- Generalization: Agents trained with SRMT can often perform well in environments different from those they were trained in.
SRMT in Action: The Bottleneck Task
To test SRMT, the researchers created a simple but challenging scenario: two agents need to pass through a narrow corridor to reach their goals on opposite sides. This "bottleneck" task requires coordination to avoid getting stuck. The results were impressive:
- SRMT consistently outperformed other methods, especially when rewards were sparse (i.e., when the agents received little feedback from the environment).
- Agents trained with SRMT could generalize to much longer corridors than they had seen during training, showing the method's robustness.
Scaling Up: Lifelong Multi-Agent Pathfinding
While the bottleneck task is a good test, real-world applications often involve more complex scenarios. The researchers also evaluated SRMT on more challenging "lifelong" multi-agent pathfinding tasks, where agents continuously receive new goals. In these tests, SRMT demonstrated:
- Competitive performance against state-of-the-art methods on various map types (mazes, random environments, and realistic city layouts).
- Strong generalization to unseen maps and different numbers of agents.
- Efficient scaling as the number of agents increased.
How SRMT Works Under the Hood
Let's break down the key components of SRMT:
- Spatial Encoder: This part processes what each agent sees in its local environment.
- Recurrent Memory: Each agent maintains a memory that's updated over time, allowing it to remember important information.
- Shared Memory Mechanism: This is where the magic happens. Agents' individual memories are pooled and made accessible to all agents.
- Attention Mechanisms: Borrowed from transformer architectures, these allow agents to focus on the most relevant information in the shared memory.
- Actor-Critic Network: This part of the model learns to make decisions (the "actor") and estimate how good those decisions are (the "critic").
By combining these elements, SRMT creates a powerful framework for multi-agent coordination without requiring explicit rules or centralized control.
Implications and Future Directions
The success of SRMT opens up exciting possibilities for multi-agent systems:
- Robotics: Improved coordination could lead to more efficient warehouse operations or search-and-rescue missions.
- Traffic Management: Self-driving cars could better coordinate their movements in complex urban environments.
- Game AI: More sophisticated and cooperative non-player characters in video games.
- Swarm Intelligence: Coordinating large groups of simple robots or drones for tasks like environmental monitoring.
Future research might explore:
- Combining SRMT with other planning algorithms for even better performance.
- Applying the shared memory concept to other types of multi-agent tasks beyond pathfinding.
- Investigating how SRMT scales to even larger numbers of agents and more complex environments.
Conclusion
The Shared Recurrent Memory Transformer represents a significant step forward in multi-agent reinforcement learning. By enabling implicit communication through shared memory, it offers a scalable and flexible approach to coordination in decentralized systems. As we continue to develop more sophisticated AI systems, approaches like SRMT that draw inspiration from cognitive science and leverage advanced machine learning architectures will likely play an increasingly important role in solving complex real-world problems.