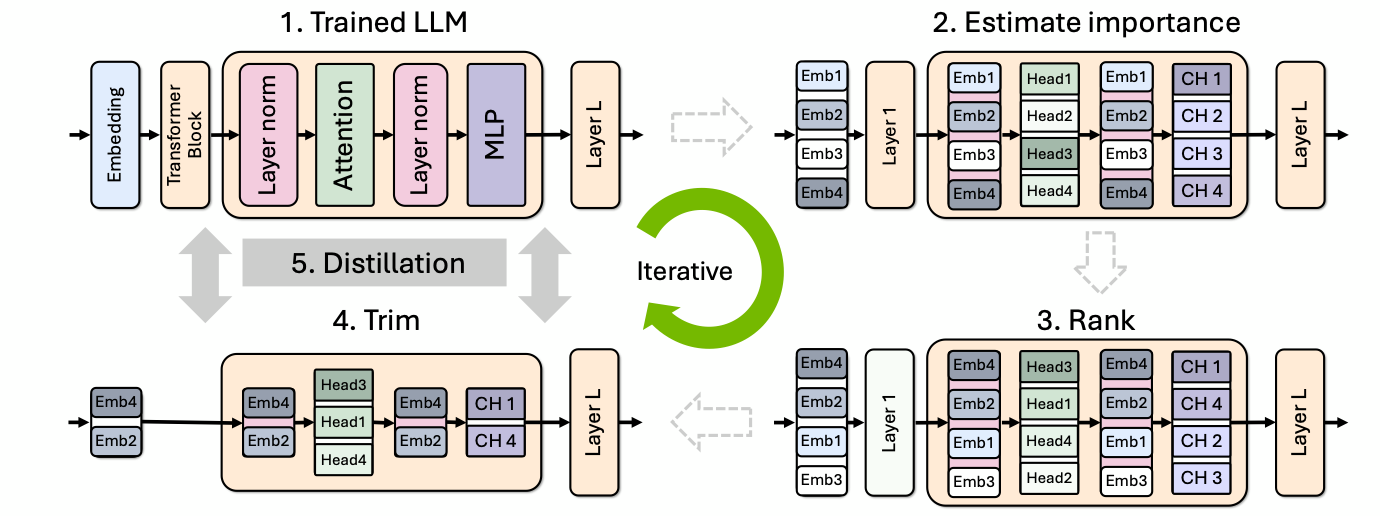
NVIDIA's research team has introduced an innovative approach to developing smaller, yet highly accurate language models by leveraging structured weight pruning and knowledge distillation. These techniques are designed to streamline the model without compromising its performance, offering several key benefits for developers and organizations focused on AI development.
Key Benefits and Innovations:
-
Performance Improvement:
- The refined models achieve a 16% improvement in MMLU (Massively Multilingual Language Understanding) scores. MMLU is a benchmark used to evaluate a model's understanding and processing of multilingual content, making this improvement significant for applications that require high linguistic accuracy across different languages.
-
Training Efficiency:
- The method reduces the number of tokens required to train new models by a factor of 40. Tokens are the building blocks of language models, and reducing their number drastically cuts down on computational resources and time needed for training, allowing for faster development cycles.
-
Cost Savings:
- The new approach delivers up to 1.8x cost savings when training a family of models. This is particularly beneficial for enterprises and developers working on a range of models, as the savings in computational costs can be substantial.
Application to Meta's Llama Models:
The effectiveness of NVIDIA's method is demonstrated through its application to Meta's Llama 3.1 8B model. By applying structured pruning and distillation techniques, the model was effectively reduced and optimized into the Llama-3.1-Minitron 4B. This smaller model retains much of the original's accuracy and functionality but is far more efficient to run and train.
Availability and Resources:
- Model Collection: The Llama-3.1-Minitron 4B and related models are available on Hugging Face, providing developers with access to pre-trained models that can be fine-tuned for specific tasks.
- Technical Insights: For those interested in the technical aspects, a detailed explanation of the pruning and distillation process is available in a technical blog from NVIDIA.
- Research Foundation: The underlying research that supports these innovations is documented in a comprehensive research paper, offering insights into the methodologies and experiments that led to these advancements.
This approach by NVIDIA not only highlights the potential for creating more efficient AI models but also sets a new standard in how large language models (LLMs) can be optimized for performance and cost-effectiveness without sacrificing accuracy.