





Now that I have your attention with that suspiciously simple title, let's be honest: evaluating AI systems is anything but a piece of cake. However, thinking about AI evaluations like a layered cake can help us understand the various levels of assessment needed for a robust evaluation framework.
Just as a master baker carefully constructs a wedding cake with distinct layers - each contributing its own flavor and texture to the whole - AI evaluation requires multiple layers of assessment working in harmony. From the foundation layer of basic accuracy metrics to the delicate frosting of user experience evaluation, each layer serves a crucial purpose.
Think of it this way: You wouldn't serve a cake without testing each component. The base needs to be sturdy, the filling must complement each layer, and the frosting should tie everything together. Similarly, your AI system needs evaluation at every level - from individual model responses to end-to-end system performance.
By the end of this article, you'll understand how to build a systematic evaluation pipeline that catches potential issues before they impact your users. We'll slice through each layer of AI evaluation, giving you the recipe for success in deploying GenAI applications.
Technical Background: The Evaluation Challenge
Just as a cake needs different ingredients that work together, evaluating generative AI applications presents unique challenges that traditional software testing frameworks don't address. Unlike deterministic systems where inputs map to predictable outputs, GenAI models can produce varied, context-dependent responses that require nuanced evaluation approaches.
Traditional evaluation methods often fall short in three critical areas:
- Consistency Assessment: Models may provide different outputs for similar inputs
- Context Preservation: Ensuring responses maintain relevant context across interactions
- Quality Metrics: Defining quantitative measures for qualitative outputs
Current approaches typically rely on manual review processes or simple accuracy metrics, neither of which scales effectively for production deployments. To address these limitations, HP Inc. has partnered with Galileo (Galileo Homepage) to provide a new product we call HP GenAI Lab.
By bringing together our existing product AI Studio which provides secure, containerized development environments with an industry leader in AI evaluation and observability we are bringing together the fragmented AI development workflow into a single solution.
Practical Example: Evaluating a RAG application for Product Managers
I’m not going to go into details on the entire model pipeline, but to get you started I will provide some basic context and the code that leads up the evaluation pipeline. I work as a product manager here at HP leading the efforts around HP GenAI Lab, so I built a basic RAG application that allows me to ask questions centered around product growth tactics.
I didn’t spend a lot of time optimizing the chunking or embedding strategy, but to demonstrate how you can use HP GenAI Lab and Galileo to rapidly experiment and evaluate your results I performed three separate evaluation runs implementing different chunk sizes for the respective evaluation runs, i.e., 300, 400 and 500 tokens.
Building Your Evaluation ‘Layer Cake’
Let's build a comprehensive evaluation pipeline that addresses the core challenges of GenAI assessment. We'll start with first layer which provides us the broadest level of evaluation.
We use the Galileo ‘promptquality’ SDK in Python to set up the evaluation pipeline. As a quick sidenote, for those AI developers that are more comfortable with Typescript there is also a Typescript variant of the SDK that you can try out as well.
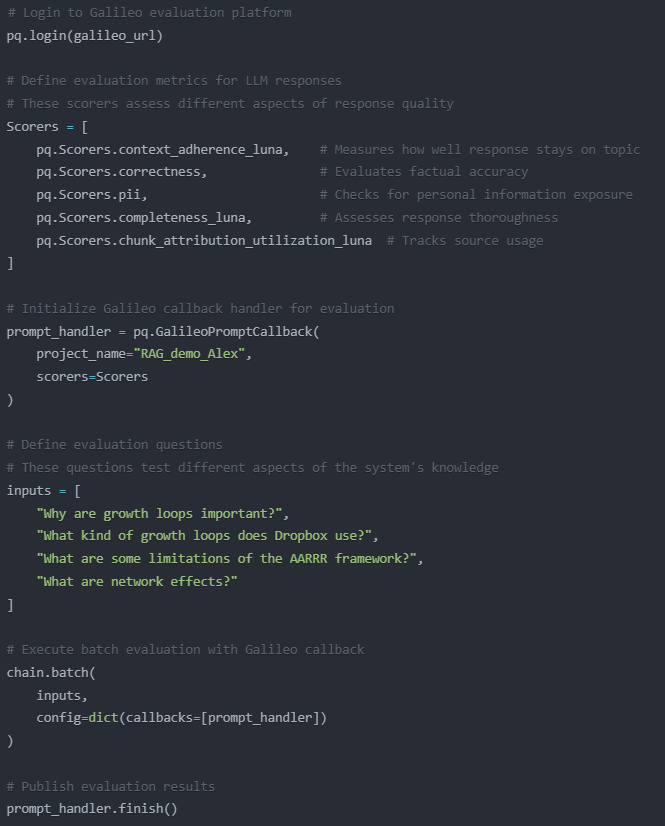
Our evaluation set is the 4 questions highlighted in green and denoted as the ‘inputs’ to the LLM.
Looking at average performance for our various evaluation metrics (denoted as ‘Scorers’ in the above code) serves as our first layer of evaluation and will give us a broad understanding at how well the model is performing overall. To do so I employed 3 metrics more commonly known as the ‘RAG Triad’ which consists of Groundedness, Context Relevance and Answer Relevance.
It's a comprehensive evaluation framework that checks three critical dimensions of Retrieval-Augmented Generation (RAG) systems:
1. Context Relevance: Ensuring retrieved information is actually meaningful to your question
2. Groundedness: Verifying that AI responses stick to the facts provided in your context
3. Answer Relevance: Confirming the response genuinely answers the original question
By rigorously testing these three areas, we can dramatically reduce AI hallucinations and build more trustworthy AI applications.
Looking at a single evaluation run that measures the average value of each of these metrics across the 4 questions of our evaluation set we can see Context Adherence, aka Groundedness, is rather low indicating the potential for hallucinations.
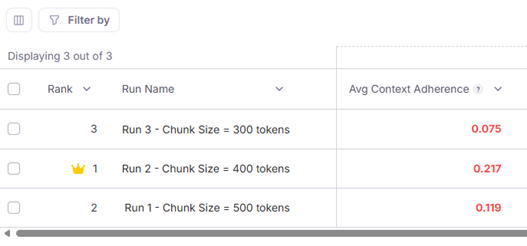
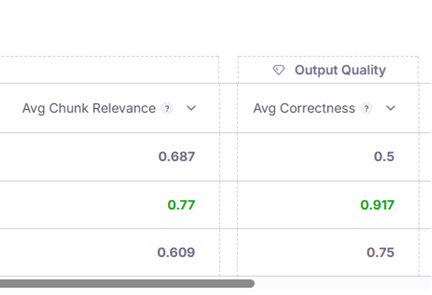
But when we look at the other metrics for that run we see that the chunks utilized to answer the 4 questions of our evaluation set we see that the Chunk Relevance, aka Context Relevance, and the Correctness, aka Answer Relevance were quite high, approaching the maximum values of 1.
Diving deeper into the next layer of the Evaluation ‘cake’
While we are pleased with the context relevance and correctness across the 4 questions of our evaluation set, we probably want to dive a bit deeper, and we can do exactly that using Galileo as part of HP GenAI Lab.
We move beyond averages and begin to look at the metrics for each of the 4 questions we asked of the LLM.
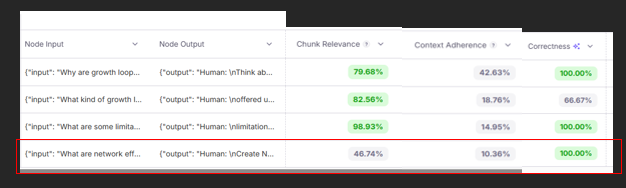
We can see that chunk relevance is really high for all questions except for the 4th question in our evaluation set which also happens to have very low context adherence as well. The counter to that is that answer correctness is very high, indicating that the answer is factually correct in spite of the low context relevance and context adherence.
Having factually correct answers is what we are aiming for, but we need to understand why that wasn’t informed by good context so we can actually go another level deeper.
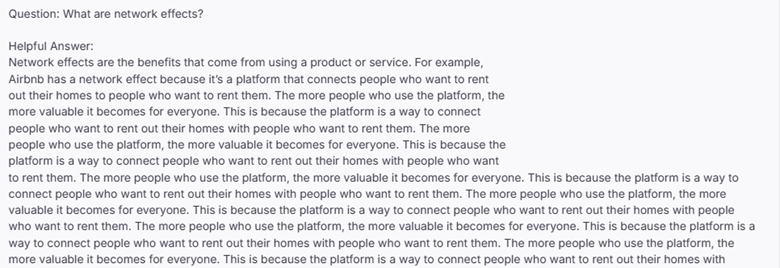
By double clicking on that particular question of “What are network effects?”, we get a wealth of information around what context was actually being pulled as part of the RAG pipeline.
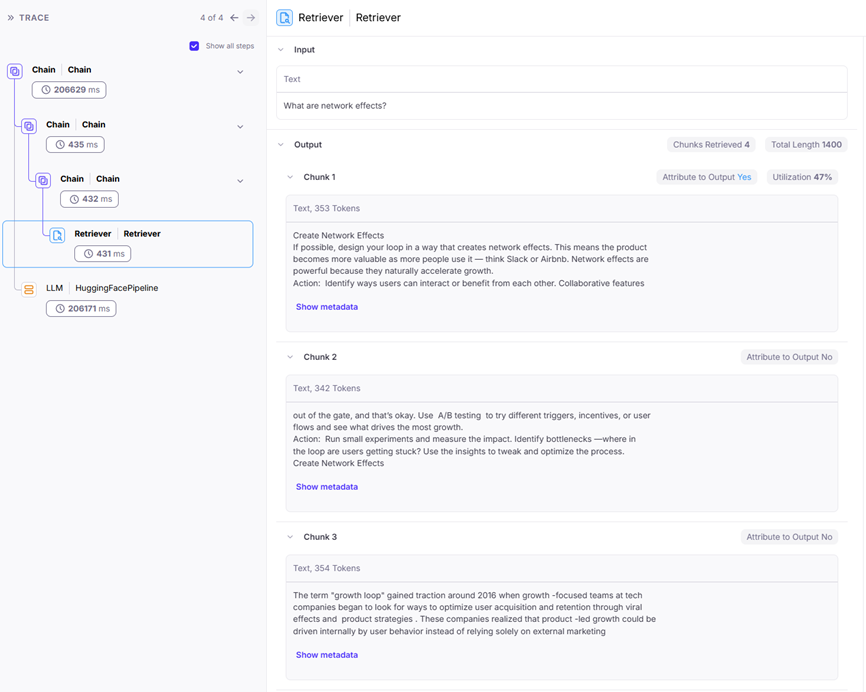
By examining the individual chunks pulled by the Retriever component of our pipeline we see that the context ‘talks around’ network effects and why they are good without actually adding much to detail as to what they really are.
This is really good information to know because it gives us some indication that we may want to go back and fix this by performing corrective actions such as finetuning the embedding model to provide more relevant context.
We could stop there, but if we really wanted to go another layer deeper we can see which of these context chunks and which pieces of the context actually contribute to the model output by utilizing the metrics Chunk Attribution and Chunk Utilization that Galileo provides as part of HP GenAI Lab.
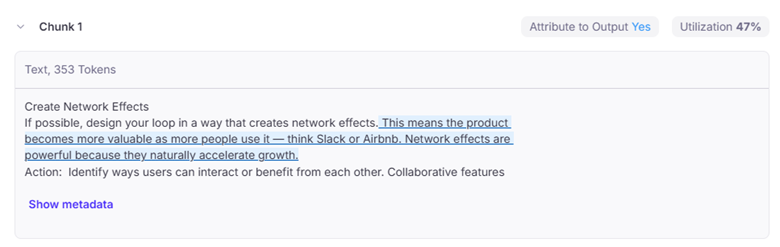
Chunk 1 was the only chunk that contributes to the output provided by the LLM and within that chunk the text highlighted in blue is what the LLM utilized to form the answer to our question.
Conclusion
Just as a master baker knows that the true quality of a cake can only be assessed by examining each layer, we've seen how AI evaluation requires a systematic, multi-layered approach. Through our practical example using HP GenAI Lab and Galileo, we've demonstrated how to slice through each layer of evaluation - from broad metrics averages to granular chunk attribution analysis.
The power of this layered approach becomes evident when we discover insights that wouldn't be visible from a surface-level assessment alone. As we saw in our RAG example, what appeared to be a correct answer actually lacked proper context support - an insight we could only uncover by diving deeper into our evaluation layers.
By bringing together secure development environments through AI Studio and comprehensive evaluation capabilities through Galileo, HP GenAI Lab provides the complete toolkit needed to build and assess GenAI applications with confidence.
The key to successful AI evaluation lies in the careful attention paid to each layer. By implementing these evaluation strategies, you're not just testing your AI system - you're building a foundation for reliable, trustworthy AI applications that truly serve your users' needs.
Call to Action
If you’d like to learn more and get signed up for upcoming early access program for HP GenAI Lab please feel free to reach out to myself (curtis.burkhalter@hp.com), or our HP AI and Data Science Community leads Sothan (sothan.thach@hp.com) and Matt (matt.trainor@hp.com).